Simple lockfree IPC using shared memory and C11
I have an interesting Linux application that requires a process with one or more real-time threads to communicate with other processes on the system. The use case is single producer with single consumer per IPC channel.
The real-time requirements of the application (this runs on a kernel with the PREEMPT RT patch set applied) requires that the IPC channel is lock-free and presents minimal overhead. That is, a real-time producer thread or process must be able to quickly write something and keep executing without locking or context switches.
I decided to prototype a simple IPC mechanism while looking at a few techniques like userspace RCU as well. This is very much a work in progress and I am not sure how useful it really is but I am posting it here in case it is interesting or even leads to some discussion.
Shared Memory
There are several ways of implementing IPC in Linux and I chose the simple POSIX shared memory approach to represent IPC “channels”:
- One process (the producer) creates a POSIX shared memory object and sizes it according to the IPC API contract.
- Another process (the consumer) opens this shared memory object.
Both processes use mmap() to map a window into this shared memory and can now
communicate:
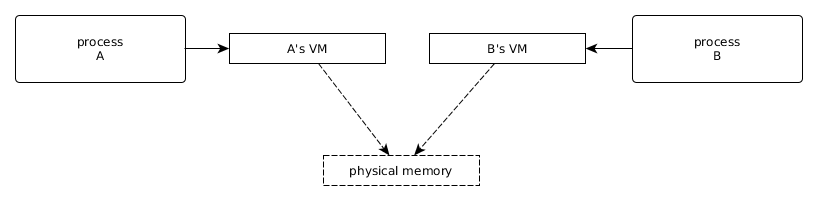
Stack Structure
We then need a data structure such as a stack or list that both processes can use to move data around in this window and this in turn cannot be dynamically allocated (instead is mapped into the window) and we cannot pass around pointers since each process sees the same window in its own address space. In addition, the data structure must support concurrent access.
The approach I took involves placing the data structure itself (or the “management” portion) into the start of the shared window, followed by a buffer that the data structure manages. This works just like an implementation of a stack or list that has all of its nodes allocated up front except here we also place everything in a set location in memory (or rather cast a particular memory location).
I chose a simple stack data structure and based my design on the C11 Lock free Stack written by Chris Wellons. This
does use the C11 stdatomic.h primitives so GCC 4.9 or newer is required to
compile and GCC should be told to be in C11 mode (for example with -std=c11).
GCC switched to C11 by default in version 5.0 so that is now the default if you
do not specify -std= otherwise.
This stack maintains two pointers: a head and free which point into the
pool of stack nodes. Data is added by pushing onto the head (the new node
comes from the free stack) and is removed by popping off the head (and thereby
returning the node to the free stack). There are, however, no real pointers
since we are not directly working with physical memory. In place of pointers I
am using indexes or offsets which in turn resolve to a memory location when
needed (that is, we manually implement base plus offset addressing). The
memory window is represented as follows:
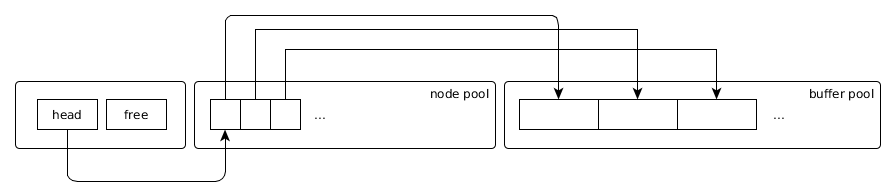
There is a one to one mapping of stack nodes to buffer pool locations (offsets) and, by knowing the starting address of the data structure, we can always calculate a pointer to some offset in the buffer pool.
Machine capabilities and limitations
This approach assumes that the machine in question is capable of compare and
swap (CAS) and most of them (modern ARM, PowerPC, x86, etc) are. The C11
generic function atomic_compare_exchange_weak will generate suitable CAS instructions.
Machines do vary in the CAS size they support (among other things), that is how many bytes can be atomically compared and swapped. There is a set of Atomic lock-free constants that should be checked to determine what the machine is capable of.
The CPU I am targeting for example does not support “double CAS” and therefore cannot compare and swap a pointer and ABA counter in one shot. On the other hand, I am using base plus offset addressing rather than pointers and I have a finite number of “slots” that I need to address so the size of the “pointer” (offset) can be adjusted such that it, plus an ABA counter, can “fit” into the CAS capability of the machine.
Data Structures
The machine I am targeting can CAS four bytes so this can represent a stack “head” pointer:
struct lfs_head {
uint16_t inode; /* offset into the node pool */
uint16_t count; /* ABA counter */
};
The “nodes” themselves are nothing more than a next “pointer” which in turn is just a 16-bit value representing another offset into the node pool,
struct lfs_node {
uint16_t inext; /* offset into the node pool */
};
An offset value of 0 corresponds to the 0th element so some kind of special
value is needed to describe a “null pointer”, I chose:
#define NULL_INDEX 0xFFFF
since I do not intend to support very deep stacks in this design. An index can
then be checked against NULL_INDEX just like a check for NULL.
The stack “descriptor” itself contains a number of elements including the stack
head and free “pointers”. It is set up at initialization and then modified as
needed by push and pop operations. We would normally have pointers here to
the stack node pool and buffer pool, however with the shared memory window
design this is not possible and, given the fixed layout in memory, we can easily
calculate those locations as offsets from the location of the descriptor (at
the start of the buffer).
typedef struct {
size_t depth; /* Number of nodes (and corresponding data buffers) */
size_t data_nb; /* Size of each data buffer, in bytes */
_Atomic struct lfs_head shead, sfree; /* stack and free stack */
_Atomic size_t size; /* Number of nodes on the stack */
} __attribute__((packed)) lfs_t;
This descriptor implies that
- The node pool is located at the address of this descriptor plus the size of the descriptor.
- The Nth node is located at the address of the node pool plus the size of a node multiplied by
N - The buffer pool is located at the address of the node pool plus the size of the node pool (which in turn is the size of a node multiplied by the
depth). - The Nth buffer is located at the address of the buffer pool plus the size of one buffer,
data_nb, multiplied byN.
API
The lock-free stack (LFS) itself must be initialized and this in turn needs to know where the descriptor is, the desired stack depth, and how big the buffers in the buffer pool are (the latter is used to calculate data pointers from the internally managed offsets).
void lfs_init(lfs_t *lfs, size_t depth, size_t data_nb);
From there, arbitrary data can be pushed to the stack as long as there are one or more free nodes. The data is copied into the corresponding buffer and the size is known from initialization time.
bool lfs_push(lfs_t *lfs, void *value);
Data can be popped off the stack as well:
void *lfs_pop(lfs_t *lfs);
And the number of nodes on the stack is tracked and available:
size_t lfs_size(lfs_t *lfs);
Implementation
The LFS internally must implement push and pop which in turn are called by
the lfs_push and lfs_pop routines.
lfs_pop will:
popa node from the stackpushthat node to the free stack- adjust the
sizebook keeping -
return the buffer pool pointer corresponding to that node
void *lfs_pop(lfs_t *lfs) { /* Pull a node off the stack */ uint16_t inode = pop(lfs, &lfs->shead); if (inode == NULL_INDEX) { return NULL; /* There was nothing on the stack */ } else { /* We pulled a node off so decrement the size */ atomic_fetch_sub(&lfs->size, 1); /* Place this node onto the free stack */ push(lfs, &lfs->sfree, inode); /* Resolve the corresponding buffer pointer */ return get_node_value(lfs, inode); } }
lfs_push will:
pulla node from the free stack- copy data into the buffer pool location corresponding to that node
pushthat node into the stack-
adjust the
sizebook keepingbool lfs_push(lfs_t *lfs, void *value) { /* Pull a node off the free stack */ uint16_t inode = pop(lfs, &lfs->sfree); if (inode == NULL_INDEX) { return false; /* There was no room. */ } else { /* Copy the data into the buffer corresponding to this new node */ memcpy(get_node_value(lfs, inode), value, lfs->data_nb); /* Place the node into the stack and increment the stack size */ push(lfs, &lfs->shead, inode); atomic_fetch_add(&lfs->size, 1); return true; } }
lfs_size simply loads and returns the size field contents:
size_t lfs_size(lfs_t *lfs)
{
return atomic_load(&lfs->size);
}
Initialization
The initialization routine sets up the data_nb and depth fields that we use
to calculate pointers at run time and also sets initial values for the stack
heads and nodes.
void lfs_init(lfs_t *lfs, size_t depth, size_t data_nb)
{
lfs->data_nb = data_nb;
lfs->depth = depth;
The initial state for the stack head is to point to NULL (empty stack) and we
set the size accordingly:
lfs->shead.count = ATOMIC_VAR_INIT(0);
lfs->shead.inode = ATOMIC_VAR_INIT(NULL_INDEX);
lfs->size = ATOMIC_VAR_INIT(0);
Each node in the node pool points to the next node while the last one points to NULL.
struct lfs_node *nodes = get_node_pool(lfs);
/* Initialize the node pool like a linked list. */
for (size_t i = 0; i < depth - 1; i++) {
nodes[i].inext = i + 1;
}
nodes[depth - 1].inext = NULL_INDEX; /* last node */
The entire stack is free. The free head therefore points to the 0th node in the node pool:
/* The free pool "points" to the first node in the node pool */
lfs->sfree.inode = ATOMIC_VAR_INIT(0);
lfs->sfree.count = ATOMIC_VAR_INIT(0);
}
Internal Implementation
The location of the node pool can be calculated at any time by knowing the location of the descriptor and the size of the descriptor:
static struct lfs_node *get_node_pool(lfs_t *lfs)
{
return (struct lfs_node *)((char *)lfs + sizeof(*lfs));
}
We can calculate the data pointer (into the buffer pool) for a given node by using an offset from the node pool location:
/* Resolve a node by its index and then find the corresponding pointer into the
* buffer pool. */
static void *get_node_value(lfs_t *lfs, uint16_t inode)
{
if (inode < lfs->depth) {
return (char *)lfs + sizeof(*lfs) +
lfs->depth * sizeof(struct lfs_node) +
inode * lfs->data_nb;
} else {
return NULL;
}
}
The internal implementation consists of push and pop methods that make use
of the stack represented by the LFS descriptor.
Lock-free push
The lock-free push implementation needs a pointer to the head it is working
with (so that we can use it for both the normal and free stack while also
knowing about the underlying descriptor) as well as the node we are pushing
(passed by an index into the node pool). This routine must:
- load the current head
- build the new head which in turn:
- has an ABA counter that is one greater than that of the original head (this is done to partially solve the ABA problem).
- points (by index) to the node we are pushing onto the stack
-
set up the new node with a
nextpointer corresponding to the original headstatic void push(lfs_t *lfs, _Atomic struct lfs_head *head, uint16_t inode) { struct lfs_head next, orig = atomic_load(head); struct lfs_node *nodes = get_node_pool(lfs); do { nodes[inode].inext = orig.inode; next.count = orig.count + 1; next.inode = inode; } while (!atomic_compare_exchange_weak(head, &orig, next)); }
Lock-free pop
The lock-free pop implementation also must know the head it is working with
(again so that we can use it for both the normal and free stack) and it in turn
returns the node that is removed, by index. This method must:
- load the current head
- build a new head that:
- has its
nextpointer set to that of the original head - has its ABA counter set to one greater than that of the original head (again this is to partially solve the ABA problem).
-
return the removed original head
static uint16_t pop(lfs_t *lfs, _Atomic struct lfs_head *head) { struct lfs_head next, orig = atomic_load(head); struct lfs_node *nodes = get_node_pool(lfs); if (orig.inode != NULL_INDEX) { do { next.count = orig.count + 1; next.inode = nodes[orig.inode].inext; } while (!atomic_compare_exchange_weak(head, &orig, next)); } return orig.inode; }